はじめに
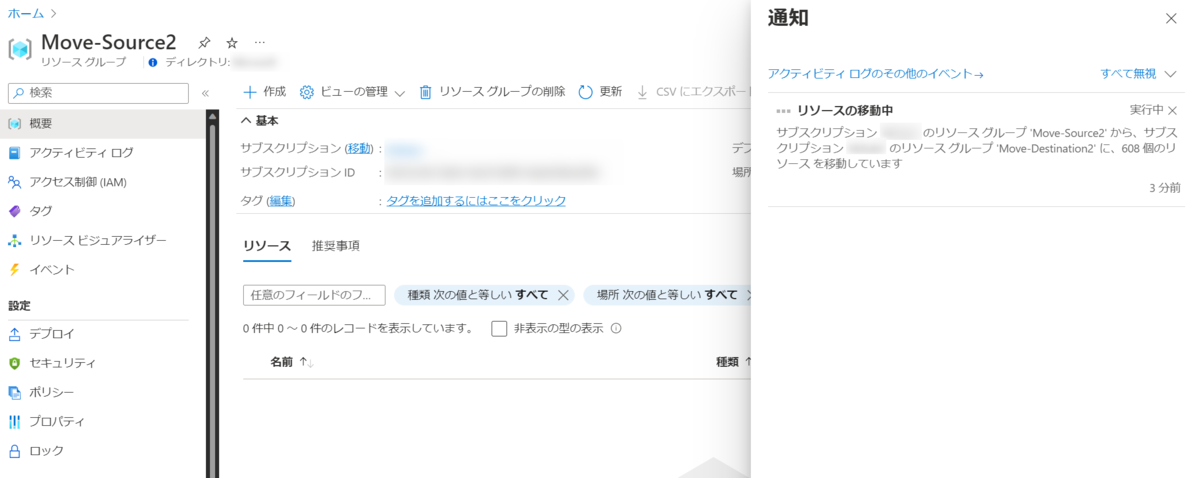
今回はコスト可視化の試みとして、リソース グループ毎に先月との差額はどれくらいか?を表示できるようにしてみました。
Cost Management でも予測やグルーピングなどそれなりに充実しているんですが、 "先月"、"過去〇日" という選択しかできず、 先月と比較する、というような表示の仕方ができなかったので、それっぽいものを Azure Monitor のブックで作ってみました。
細かい見栄えとかまで考えると完璧ではないのですが、目的は果たせていると思います。
作るのめんどい場合は以下の GitHub から Deploy to Azure をポチーでどうぞ。
目次
作りたいもの
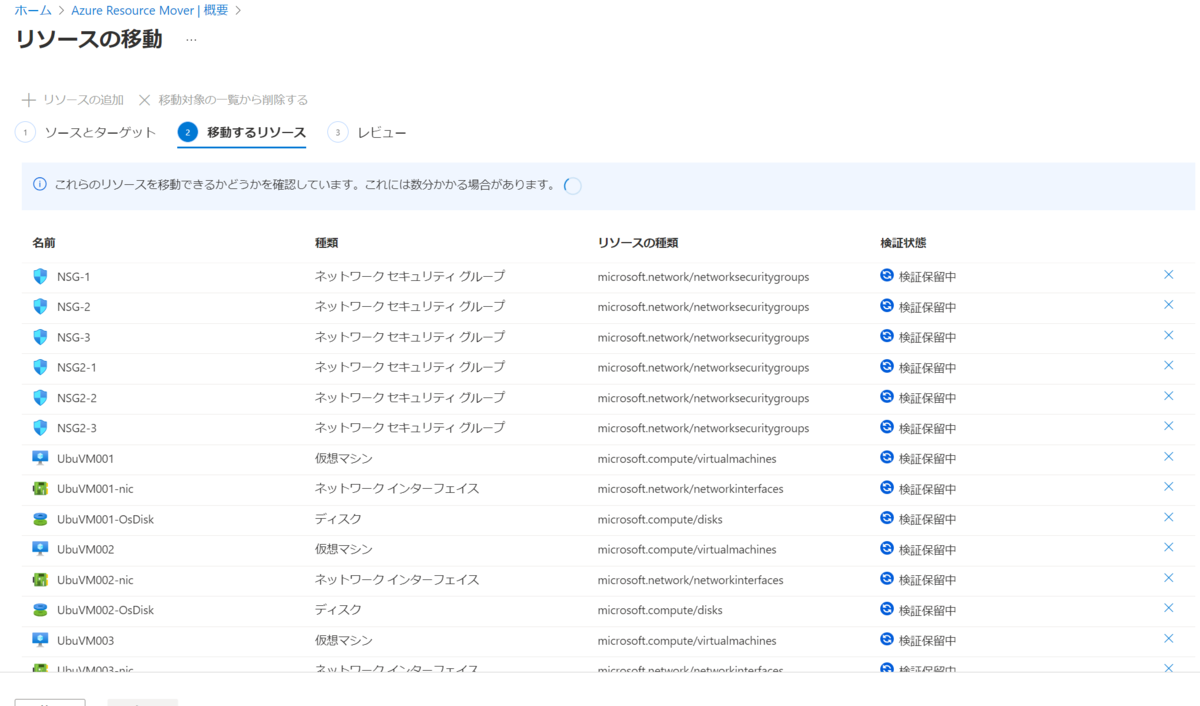
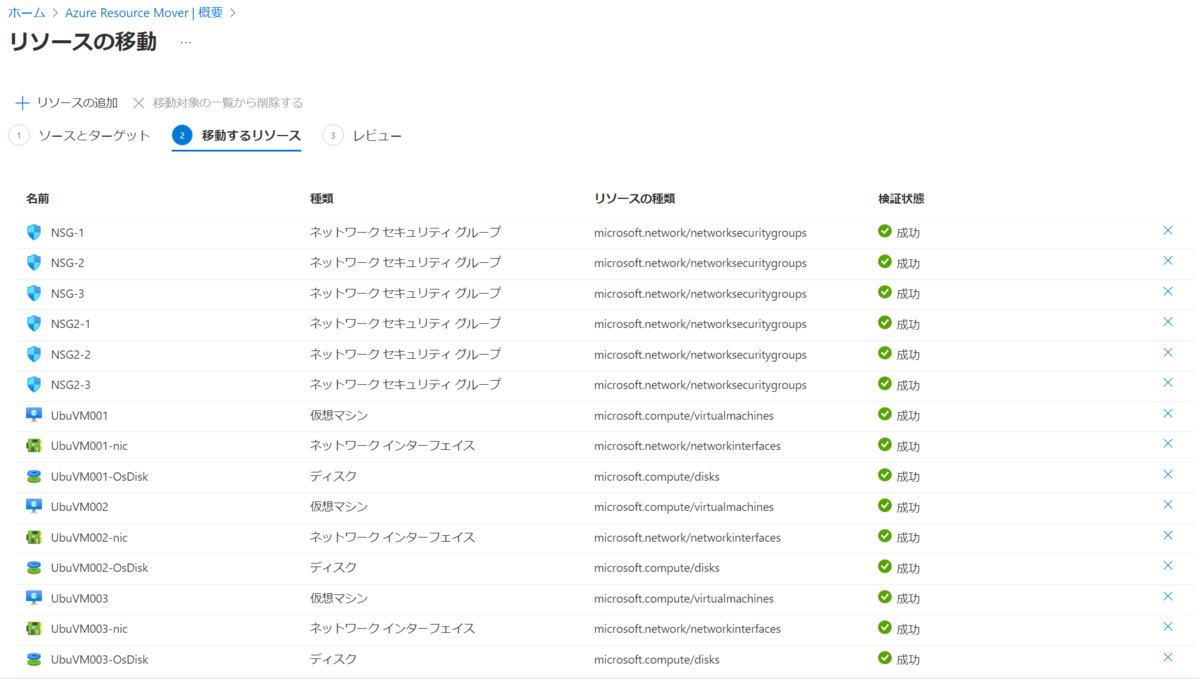
作りたいのは前述のとおり、リソース グループ毎に、先月と今月の利用料金を求め、差額を算出することです。
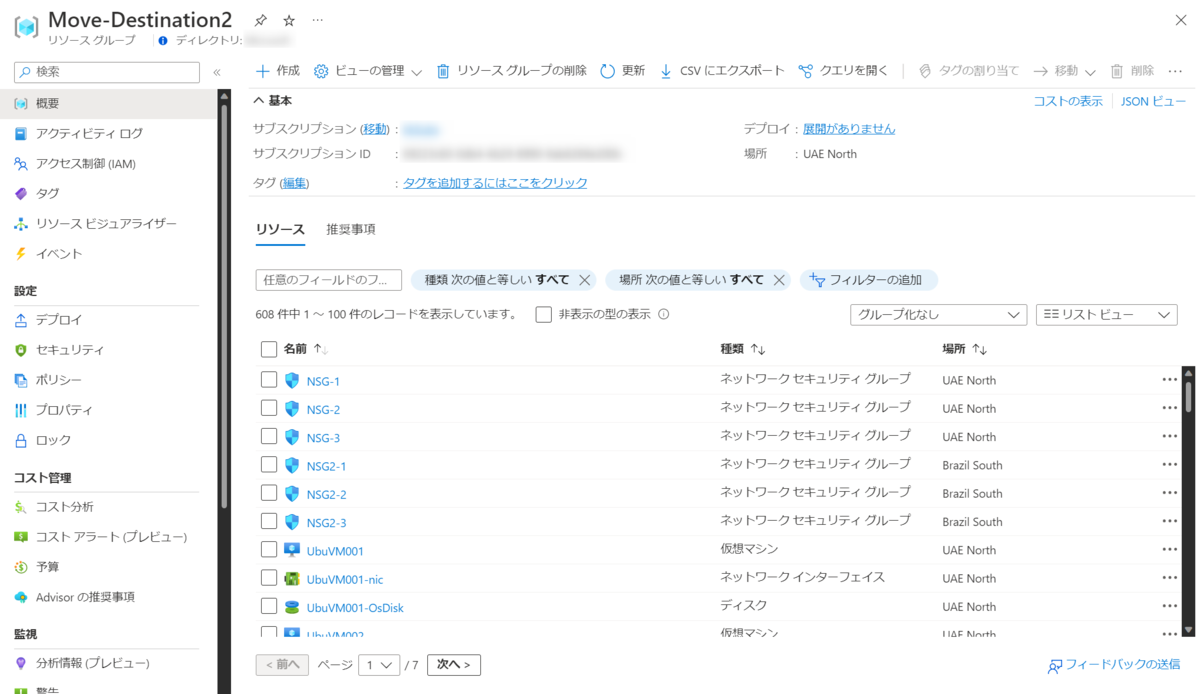
最終的には 1 レコードを "リソース グループ名、RG へのリンク、先月の料金、今月の料金、差額" としてテーブルにしたいと思います。
見た目としてはこんな感じです。

最終結果テーブルの見栄えについて補足
- リソース グループ名が空欄の箇所がある?
料金を取得したときに、リソース グループに属さない判定となっている料金や、リソース グループは存在するけど料金が 0 の場合にそうなるようです。
それはそれで情報となるので、これ以上時間はかけずこれで OK としました。
- リソース グループへのリンクが空欄の箇所がある?
Resource Graph で動的に、ブックを見たその時存在しているリソース グループの情報を取得しているので、既に削除されているリソース グループはリンクがなしになります。
- 先月または今月の利用料金が空欄の箇所がある?
先月は料金が発生したが先月の内に削除された、今月新しく作られ料金が発生した、などはそのようになります。
- 差額がマイナスだったら 0 にできない?
したいと思ったけど列の設定に該当しそうなものを見つけられなかったので諦めました。
ブック
Azure Monitor の機能の 1 であり、メトリックやログなどいろいろなデータ ソースとパーツを使って、対話型の分析・可視化を行うことができる機能です。
ビューを提供する、という点では Azure ダッシュボードも存在していますが、ブックは対話型である点が大きく違います。
例えばサブスクリプションを選ぶパラメーターを作り、それを変更することで表示結果を変える、ということなどができます。
今回はこれを使います。
ブックの作成
全体像
初めに、完成系を作るために必要なものをまとめます。

API もしくは Resource Graph から作ったテーブルが計 3 つ、それをベースにマージして中間テーブル (3-1 から 3-3) を作り、再度マージして目的のテーブルを作成しました。
最適化できる余地があるのかもしれませんが、思いつかなかったのでこの方法で記載します。
(1) から順に作り方をまとめます。
パラメーター作成
(1) から順番にとは言ったのですが細かいところで、パラメーターを先に作成します。
可視化対象のサブスクリプションをドロップダウン リストから選択できるようにしています。

作り方
空のブックを作成し、"パラメーター" を追加します。


"パラメーターの追加" から以下のように Subscription 選択用のパラメーターを追加します


これでドロップダウン リストが完成です。
(1) 今月のリソース グループ毎の利用料金
利用料金のテーブルは、Azure Resource Manager の API を叩いて取得します。
ここにやりたいことは大体書いてあるので、こちらも読んでみてください。
以下の Usage API があるので、これをブックから実行し、データを取得します。
作り方
"クエリ" を追加します。
Usage の API に従い、以下のように設定します。
- データ ソース : Azure Resource Manager
- HTTP メソッド : POST
- パス : /subscriptions/{Subscription:id}/providers/Microsoft.CostManagement/query
パスの {Subscription:id} は、1 つ前の手順で作成した Subscription パラメーターを指す記法です。 パラメータの選択にあわせてデータの取得先が変更されるように、このとおり記載します。
URL パラメーターとしては、api-version を 2019-11-01 に指定します。

"結果の設定" では、JSON パス テーブルを $.properties に指定します。

ボディには以下の JSON を指定します。
{
"type": "Usage",
"timeframe": "MonthToDate",
"dataset": {
"granularity": "None",
"aggregation": {
"totalCost": {
"name": "PreTaxCost",
"function": "Sum"
}
},
"grouping": [
{
"type": "Dimension",
"name": "resourceGroup"
}
]
}
}
timeframe にて、データの取得範囲を指定します。
今月のデータを取りたいので、MonthToDate を指定します。
granularity を None にすると、ひと月分がまとめて集計されます。
1 日毎のデータが欲しい場合は、Daily を指定します。
1 日毎に取ろうかと思ったのですが、整理が難しかったのでやめました。
aggregation が集計部分で、PreTaxCost の合計を算出しています。
今回はリソース グループ毎に集計したいので、grouping 部分の記述が必要です。
これを入れない場合、全リソース グループ合算した結果が返されます。
ここまで指定したら 1 回クエリを実行してみて、リソース グループ毎に結果が得られれば OK です。
通過の単位は環境により異なります。私の環境だと USD になってしまいますが、変化量の大小はわかるのでよしとします。
以降も USD の想定で設定しているところはありますが、環境に応じて ¥ (JPY) などに変更してください。
また、リソース グループ名が空欄の課金情報があるようでそれも出力されてしまいますが、課金情報には変わりないのでよしとしました。

続いて、後のために見栄えを整えておきます。
"詳細設定" タブの "ステップ名" に、後で参照するとき用に名前を付けておきます。
今月分の集計なので This Month にしました。
また、最終的にはこのテーブルは参照しないので、"この項目を条件付きで表示する" 設定を使用して非表示にします。
パラメーターにあわせて表示非表示を切り替えることもできますが、ずっと非表示にしたいので適当に指定して大丈夫です。
最後に、非表示にはしますが後でわかるよう、グラフのタイトルを付けました。

透かしのような斜線が入れば非表示設定が有効です。

これで (1) は完成です。
ここでは列名をそのままにしましたが、今月の料金だとわかる列名にした方が最後のマージの際にわかりやすいかも。
(2) 先月のリソース グループ毎の利用料金
続いて先月の利用料金を取得します。
作り方
これは (1) のテーブルと同じ方法で取得しますが、1 点だけ、ボディの timeframe を "TheLastMonth" に変更する必要があります。
他の設定は先ほどと同様です。
Timeframe の TheLastMonth は非サポートになってしまったようで、エラーが表示されるようになりました。
現在同様のことを行うには TheLastBillingMonth を指定してください。EA 契約などであれば、TheLastMonth と同様の値を取得することができます。
一方で、従量課金や Visual Studio サブスクリプションなどの場合は一致しない場合があるため注意してください。

入力したら実行し、先ほどと異なる結果であることを確認しましょう。

(1) と同様に、ステップ名、非表示設定、タイトルをつけて完成です。

ここでは列名をそのままにしましたが、先月の料金だとわかる列名にした方が最後のマージの際にわかりやすいかも。
(3-1) 今月のみ、または先月と今月の両方に存在したリソース グループ
ここからは少し変わります。
最終的には先月と今月の月額料金を比較したいため、"先月または今月に存在したリソースグループ" の一覧 (列) が必要になります。
ブックでは取得したテーブルをマージすることもできるのですが、(1) と (2) のテーブルを直接マージするのみでは、 "先月または今月に存在したリソース グループ名" をすべて重複せずに保持したテーブル (3-3) を生成する方法がないように思われました。
そのため、一旦中間テーブルを作り (3-1, 3-2)、それを組み合わせて望む結果 (3-3) を作りました。
順に解説します。
作り方
まずは、今月のみ、または先月と今月の両方に存在したリソース グループのテーブルを作成します。
"クエリ" を追加した後にデータ ソースとして "マージ" を選択、"マージを追加します" からマージを行うテーブルとその方法、およびマージするキー列を指定します。
左右のどちらにテーブルを置くかが重要なため注意してください。
左が今月のデータ (前の手順でつけたステップ名 : This Month) です。

マージにはいろいろ種類があります。
全ての説明は省きますが、ここでは "Left Outer" を使用します。
Left Outer は指定した列を基に、以下の条件でマージされます。
- 指定した列の値が、左右どちらのテーブルにも存在する場合は出力される
- 指定した列の値が、左のテーブルにのみ存在する場合は出力される
- 指定した列の値が、右のテーブルにのみ存在する場合は出力されない
ここでいう左は今月のデータ、右は先月のデータ、列はリソース グループ名 (resourceGroup) ですので、結果 "今月のみ、または先月と今月の両方に存在したリソース グループ" が取得できます。
保存してマージを実行すると得られるテーブルにて、resourceGroup 列がそのようになっているはずです。

このままでもいいのですが、ここでほしいのは resourceGroup 列だけなので、他は消してしまいます。 (消さなくてもできるけど列が増えて見づらいので個人的にはいらない)
列の名前にチェックをつけて削除ボタンを押すと消せます。ステップ名を付けておくと、こういう時に判別しやすいです。[This Month].resourceGroup だけ残します。

列の名前は後のマージに影響がでるため、ここでは変えません。
削除だけでは表が更新されないので、マージの実行をしておきます。

後述の理由によりこのテーブルを非表示にできないので、ステップ名とタイトルだけ、こんな感じで付けておきます。

これで 3-1 は完成です。
中間テーブルの場合の注意点
ここで、今回の 3-1 のようにマージにより生成されたテーブルにおける注意点を紹介します。
それは、マージにより生成されたテーブルを非表示にすると自動的に更新されず、結果が得られない (テーブルが生成されない) 状態になる、ということです。
中間テーブルが生成されない結果、当然ながら最終結果も生成されなくなってしまいます。

これはどうも現状のブックの仕様らしく、今のところは "非表示にしない" くらいしか回避方法が見つかっていません。
そのため見栄えが悪くなってしまうのですが、マージにより生成する中間テーブル (3-1 から 3-3) は非表示にしません、できません。
ちなみに、最終結果を一番上に持ってくれば (中間テーブルを下に置けば) いいのでは?という考えもありましたが、実はブック内ではパーツの順番に意味があり、参照されるよりも先にテーブルが生成されている必要があります。
そのため、一番上で (5) を生成し、(5) より後ろにおいた (3-1 から 3-3) を参照、ということはできませんでした。
こんなエラーになります。

何かいい方法があればアップデートしますが、現状は難しそうです。 (クエリ内で join で頑張るくらい?)
苦肉の策を最後に載せています。
少しわかりづらいところがありそうだったので、補足を追記します。ここで "非表示にできない" と表現しているのは、マージ元のテーブルすべてが非表示にできないわけではなく、今回のように、クエリで取得したテーブルをマージし中間テーブルを生成、中間テーブルどうしをさらにマージする、という際に、中間テーブルが非表示にできないということです。
例として、今回実施しているような以下の場合を考えます。
- クエリで取得したテーブル A と B をマージ ⇒ テーブル C
- クエリで取得したテーブル D と E をマージ ⇒ テーブル F
- マージで取得したテーブル C と F をマージ ⇒ テーブル G
この場合、テーブル A, B, D, E を非表示にしても、テーブル C, F, G は正しく表示されます。 しかし、テーブル C, F を非表示にしてしまうと、テーブル G は生成されなくなってしまいます。
マージにより生成されたテーブルを非表示にすると再利用できない、という仕様のようです。
クエリでのデータ取得は非表示でも関係なく実行するが、マージは非表示だと実行されない、ということなのかと勝手に想像しています。
(3-2) 先月にのみ存在したリソース グループ
作り方
中間テーブルその 2 を作りますが、先ほどと同様にマージを、オプションを変えて行います。
今度は Right Anti を使います。

Right Anti は指定した列を基に、以下の条件でマージされます。
- 指定した列の値が、左右どちらのテーブルにも存在する場合は出力されない
- 指定した列の値が、左のテーブルにのみ存在する場合は出力されない
- 指定した列の値が、右のテーブルにのみ存在する場合は出力される
端的に言えば右のテーブルにあるもののみ取得、です。
これで "先月にのみ存在したリソース グループ" が取得できます。
※ここでも左右の指定が重要なため注意
3-1 と同様に、必要な列だけ残します。列名はここでは変えません。

3-1 と同様に非表示にできませんので、ステップ名とタイトル名だけ付けておきます。

これで 3-2 は完成です。
(3-3) 先月または今月に存在したリソース グループ
中間テーブルの最後として、先月または今月の両方に存在したリソース グループのリストを生成します。
作り方
再度マージを使用します。

ここでは "共有体" (Union) を選択します。
これは和集合であるため、左右テーブルにある値が合算されたテーブルが生成されます。
対象として "(3-1) 今月のみ、または先月と今月の両方に存在したリソース グループ" と "(3-2) 先月にのみ存在したリソース グループ" を選択することで、 "先月または今月に存在したリソース グループ" の列が得られます。
3-1 、3-2 で列名を変えてしまうと別の列として扱われるのか、ここでうまく 1 つの列にマージされませんでしたので注意です。

不要な列を消します。rg_LeftOuter が前のテーブルなのでそちらを消します。

中間テーブルのため例によって非表示は不可です。

これで、ほしいテーブルができました。
(4) 現在のリソース グループ名とリンク
ここまでのテーブルがあれば目的は達成できるのですが、単にテキストが並んだだけの味気ない表になってしまいますし、表中から差額の大きいリソース グループを見つけた後、概要画面に簡単に遷移できたら便利だと思うので、リソース グループへのリンクをつけます。
そのためのテーブルが (4) です。
作り方
リソース グループへのリンク付きのテーブルは、Resource Graph で取得します。
"クエリ" を追加し、データ ソースで "Azure Resource Graph" を選択します。
"サブスクリプション" の項目にて、"リソース パラメーター" の "Subscription" を選択します。
これで、Resource Graph によるクエリの対象が、パラメーターの選択と連動します。

クエリとしては以下を指定します。
resourcecontainers | where type =~ "Microsoft.resources/subscriptions/resourcegroups" | project id, name
Resource Graph でサブスクリプション内のリソース グループの一覧を取得し、リソース グループへのリンクになっている列と、この後のマージ用にテキストのリソース グループ名を取得しています。
リンクになっている id 列は、実態は "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}" という文字列になっています。
これだけだとマージの際に純粋なテキストのリソース グループ名と比較ができないので、リソース グループ名のみの列も必要、という理由です。

いつものように、ステップ名とタイトルを設定します。
(4) はマージで作られたテーブルではないので、非表示設定も可能です。

(4) はこれで完成です。
(5) リソース グループ毎の前月との差額
長かった作成もあと少し、最終結果のテーブルを生成し、見栄えを整えます。
作り方
テーブルの生成
最後はこれまでに生成した (1), (2), (3-3), (4) を 3 パターン マージして作ります。
1 つ目は、(3-3) と (1) の Left Outer です。
これで、先月または今月に存在したリソース グループリストの内、今月のリソース グループに利用料金の列がマージできます。

2 つ目は、(3-3) と (2) の Left Outer です。
これで、先月または今月に存在したリソース グループリストの内、先月のリソース グループに利用料金の列がマージできます。

3 つ目は、(3-3) と (4) の Full Outer です。

Full Outer は指定した列を基に、以下の条件でマージされます。
- 指定した列の値が、左右どちらのテーブルにも存在する場合は出力される
- 指定した列の値が、左のテーブルにのみ存在する場合は出力される
- 指定した列の値が、右のテーブルにのみ存在する場合は出力される
これで、resourceGroup 列に先月と今月のリソース グループ名、PreTaxCost と PreTaxCost1 に先月と今月の料金 (事前に列名変えておけばよかった…)、id に該当リソース グループへのリンクを持つテーブルが生成できました。

上記の 4 列以外は不要なため削除し、順番を並び替えます。
また、必要に応じて列名も任意のものに変更します。
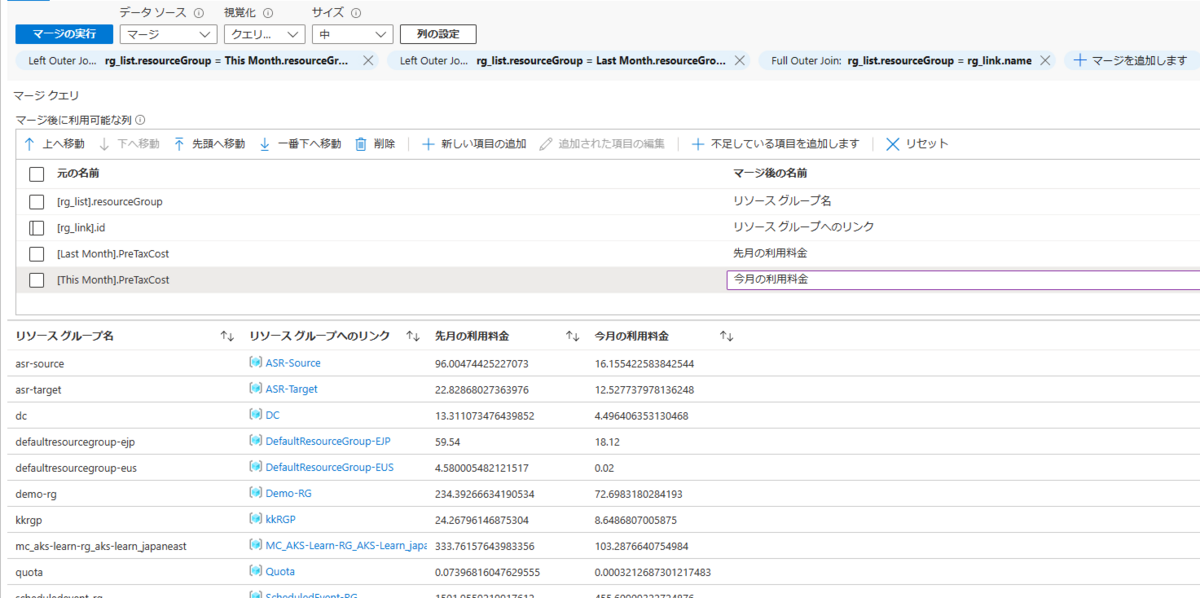
列の設定
このままでも料金の違いは判断できますが、もっとわかりやすくするため、列に設定を加えていきます。
まずは "新しい項目の追加" から新しい列を追加し、先月と今月の料金の差額を表示するようにします。
編集から、"式" を選択し、以下のように列名を使って計算式を記載します。
["今月の利用料金"] - ["先月の利用料金"]



これで再びマージすると、差額を計算した列が追加されます。名前は任意につけておきます。

続いて、料金の桁数が多すぎて見づらいので、設定していきます。"列の設定" を選択します。
"先月の利用料金" を選択し、カスタムの書式設定で以下のように設定するのがいいかと思います。この辺は見やすさなど好みです。
※通貨の単位は環境により異なります。利用している環境に応じて $ (USD) や ¥ (JPY) などに変更してください。
同様の設定を "今月の利用料金" と "差額 (今月 - 先月)" にも設定します。


この設定だとこんな感じになり、だいぶ見やすくなります。

"差額" の列には、追加でもう少し設定を加えます。
"列レンダラー" をヒートマップにして、"カラー パレット" を赤 (明るい)、"最小値" を 0 、"最大値" を任意 (ここでは 100) にします。
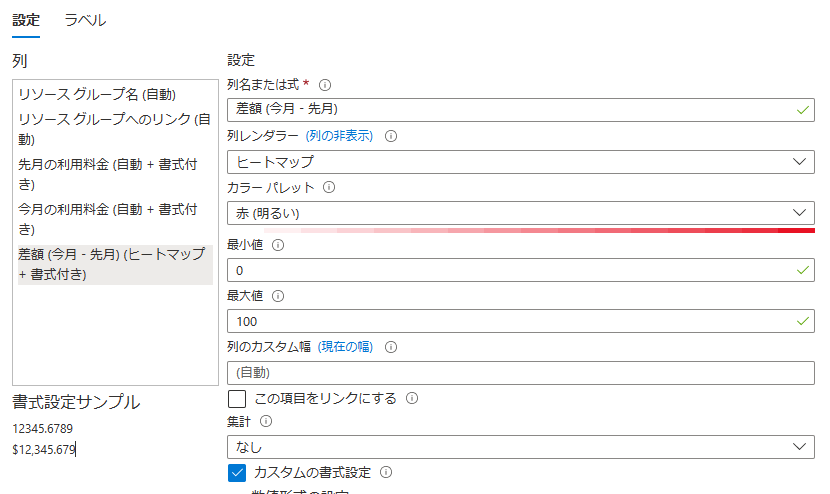
こうすることで差額の列が 0 より大きい (先月より利用料金が増えている) 場合、赤で色付けがされ、指定した値にどれくらい近いかで濃淡が変わります。
最大値を指定しなくともいいのですが、その場合は増加量が $5 であろうと $100 であろうと、列中のすべての値と比較して遠ければ薄く近ければ濃く色がついてしまい、どれくらいの重要度なのかわかりづらいように思います。
なので、五千円前後の増額を気にしたいから $40 、一万円前後の増額を気にしたいから $80、という具合に最大値を決めるといいと思います。注意点は USD なことです。
色がつくとこんな感じです。 (最大値 100 の場合)

これで、リソース グループ毎に月額料金、前月との差額を表示してくれる目的のブックは完成です!

上部の保存を忘れないようにしましょう。

ここまで読んでくれた方、試してくれた方はお疲れ様でした!
中間テーブルの非表示問題に対する苦肉の策
マージしたテーブルは非表示にできない、という話を書きましたが、見づらいので何かないか、というところで苦肉の策ですがこんな方法がありました。
(3-1) から (3-3) のテーブルに対して、サイズを "最小" とし、スタイルを以下のようにします。


何が起こるかというと、消せはしないんですが、めっちゃ小さくなります。

格好良くはないのですが、実用には足るんじゃないかと…
現状はこれくらいしかできることがなさそう…
終わりに
ということで、とてもとても長くなってしまったんですが、ブックでの料金可視化をしてみました。
ブックはテキストやメトリック、Log Analytics、Resource Graph、JSON、ARM API と実はいろいろなものが扱え、 それで得たテーブルを今回のようにマージして加工することができ、ヒートマップのような列レンダラーの種類もたくさんあってかなり多くのことが行えます。
一方で、最終的に可視したいものに対して、どこから何を取ってきて、どう組み合わせたらいいか、作り方を考えるのが少し難しい、という点はあると思います。
今回は、どうやってマージすればリソース グループの列を取得できるか?というところで苦労しました。
最初は Union でマージしてたけど、これじゃ同じ名前が 2 レコードあるじゃん!とかとか…
簡単にペタペタ貼って使えるダッシュボードに対して、簡単なものだけでなくやり込めばより複雑なものも作れるのがブック、という位置づけだと思いますが、 簡単なところからでもなかなか面白いので、こんなこともできるならやってみよーと感じてもらえたら嬉しいです。